Work Queue
The QuantumLeap Web app can offload the execution of some tasks to a work queue. In this configuration, a set of QuantumLeap Web servers add tasks to a queue and a pool of QuantumLeap queue worker processes fetch tasks from the queue and run them asynchronously, optionally retrying failed tasks. The queue data sits in Redis and QuantumLeap relies on RQ to manage it, provide worker processes to run tasks and do all the necessary bookkeeping—e.g. purging data past a configured time to live (TTL).
The QuantumLeap Web app comes with a REST API to manage work queue tasks. Clients can query, retrieve and inspect task inputs as well as task runtime information, count tasks satisfying a given predicate to gauge system load, and delete tasks. The implementation features efficient algorithms to boost performance. In particular the space complexity of queries is constant thanks to the extensive use of stream processing techniques.
The design is modular. Components hide their implementation behind interfaces and use other components only through their provided interfaces. A layered approach makes it possible to write and manage tasks at a high level, independently of the queue backend—RQ, as noted earlier. By the same token, it's possible to implement an alternative queue backend without modifying existing tasks and high-level task management modules.
At the moment, QuantumLeap only uses the work queue for NGSI notifications, if
configured to do so. When an entity payload comes through the notify
endpoint, the Web app turns the payload into a task to save it to the
DB, adds the task to the queue and returns a 200 to the client immediately.
A separate instance of QuantumLeap, configured as a queue worker, fetches the
task from the queue and runs it to actually insert the NGSI entities
into the DB, possibly retrying the insert at a later time if it fails.
Clients connect to the Web app to manage notify tasks in the queue.
Task life-cycle
The way the QuantumLeap Web app, the queue worker, RQ and Redis collaborate to process tasks is a key aspect of the QuantumLeap work queue architecture. In a nutshell, the Web app creates a task and stores it, through RQ, in a Redis hash containing the queue data. Then the worker, through RQ, fetches the task from Redis and runs it. If the task fails and retries are configured, the worker asks RQ to schedule the task to run again later and RQ puts it back into Redis. The worker retries failed tasks for a configured maximum number of times before giving up. Regardless of retries, as soon as a task runs to completion successfully, the worker notifies RQ which, in turn, saves the task back to Redis in the set of successful tasks, taking care of specifying a time to live (TTL) so Redis can automatically remove it from the set and reclaim storage past that TTL. Similarly, in the case a task fails and no retries are configured or there aren't any retries left, the worker notifies RQ which puts it into a Redis set of failed tasks, again setting a TTL so Redis can delete it automatically past that time.
The interactions sketched out so far are based on an abstract specification of the work queue task life-cycle. In fact, the above components carry out the various steps in the task life-cycle according to a finite state machine that models, with a fair degree of accuracy, how computation actually happens in the work queue and explains some important aspects we glossed over earlier, such as the relationships among retries, time and events. The UML state chart below is a visual representation of the task state machine.
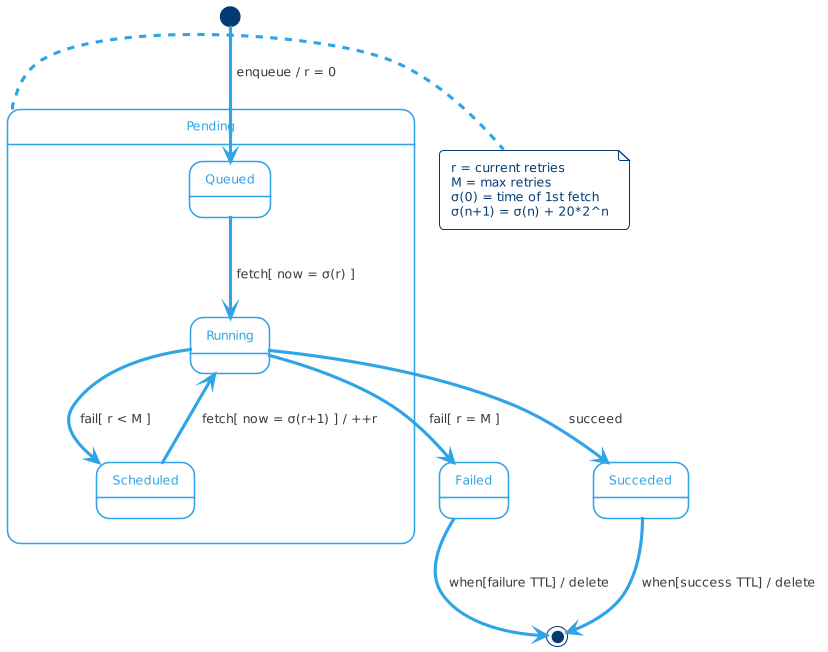
A task begins its life when the QuantumLeap Web app adds it to the work queue—enqueue
event in the diagram. At this point the task is in the Queued state
and is waiting for a queue worker process to fetch it and run it for
the first time.
Workers can retry failed tasks for up to a configured number of times
M. (M is an non-negative integer.) RQ keeps track of how many times
workers have retried a task. When the task enters the Queued state,
the current number of retries r is set to 0. A worker can retry a
task only if r < M. So if M is set to 0, workers never retry failed
tasks.
A worker initially fetches a task in the Queued state (fetch event)
at a certain time t(0) and tries to run it once. While a
task runs, it's in the Running state. After running a task, the worker
checks if the task completed successfully. If so, the task transitions
from the Running state to the Succeeded state—succeed event. On
the other hand, if the task failed, two transitions out of the Running
state are possible, depending on the current number of retries—fail
event. If r = M, the task enters the Failed state, whereas if r < M,
the worker asks RQ to schedule another execution attempt at a later
time and the task enters the Scheduled state.
The worker uses an exponential retry schedule σ. Retries get spaced out by an exponentially growing number of seconds defined by the sequence s = { c⋅2^n | k ∈ ℕ } = (c, 2c, 4c, 8c, 16c,...) where c is a constant number of seconds. (In the current implementation c = 20.) The retry schedule σ is the series of seconds defined recursively by
- σ(0) = t(0)
- σ(n+1) = σ(n) + s(n)
So σ = (t(0), t(0) + c, t(0) + c + 2c, …) and the zeroth schedule is the initial task execution at time t(0) when the worker fetched the task from the queue for the first time, the first schedule is the time point t(0) + c at which the worker retries the task for the first time if the initial run at t(0) failed, the second schedule is the time point t(0) + c + 2c at which the worker retries the task for the second time if the first retry at t(0) + c failed, and so on.
So the task may run at time point σ(k) with 0 ≤ k ≤ M.
In particular, if a task sits in the Scheduled state, at time point
σ(r+1) the worker fetches it and tries to run it again—fetch
event. Again, while the task runs, it's in the Running state. In
transitioning from Scheduled to Running, the current number of
retries r is increased by one.
A task in the Queued, Running or Scheduled state is also in the
Pending state. This is just a convenience composite state to capture
the idea that the system still doesn't know what the task outcome is
either because the task is waiting to be run for the first time, or
is scheduled for a retry or is actually busy running. The two possible
task outcomes in the model are captured by the Succeeded and Failed
state, respectively.
The Succeeded and Failed states aren't final states. In fact, as
noted earlier, RQ keeps successful and failed tasks in Redis for a
configured success and failure TTL, respectively. When that TTL expires,
Redis automatically deletes the task at which point the state machine
reaches its final state.